
•
문서를 색인하고 조회, 삭제하는 방법
•
인덱스를 생성하고 삭제하는 방법
•
문서를 검색하고 문서의 내용을 바탕으로 분석하는 방법
2. 1 문서 색인과 조회
: ElasticSearch는 JSON 형태의 문서를 저장할 수 있으며 스키마리스이기 때문에 문서를 색인하기 위해 정형화된 문서의 스키마를 미리 정의할 필요가 없다.
PUT
curl -X PUT "localhost:9200/user/_doc/1?pretty" -H 'Content-Type: application/json' -d'
> "username": "alden.akng"
> }
> '
{
"_index" : "user",
"_type" : "_doc",
"_id" : "1",
"_version": 1,
"result" : "created",
"_shards" : {
"_total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
Shell
복사
: PUT은 REST API의 메서드로 새로운 문서를 삽입할 때는 PUT, 기존 문서를 수정할 때는 POST, 삭제 DELETE, 조회 GET을 사용
: user는 문서를 색인할 인덱스 이름으로 인덱스는 문서를 저장하는 가장 큰 논리적인 단위를 의미하며 같은 성격의 문서들을 하나의 인덱스에 저장하게 됨
: _doc은 타입 이름으로 ElasticSearch 6 버전 이상에서는 하나의 인덱스에 하나의 타입만 저장할 수 있게 되었음
: 1은 문서의 ID로 ID는 인덱스 내에서 유일해야 하며 같은 ID가 입력되면 해당 문서를 수정한다고 인식
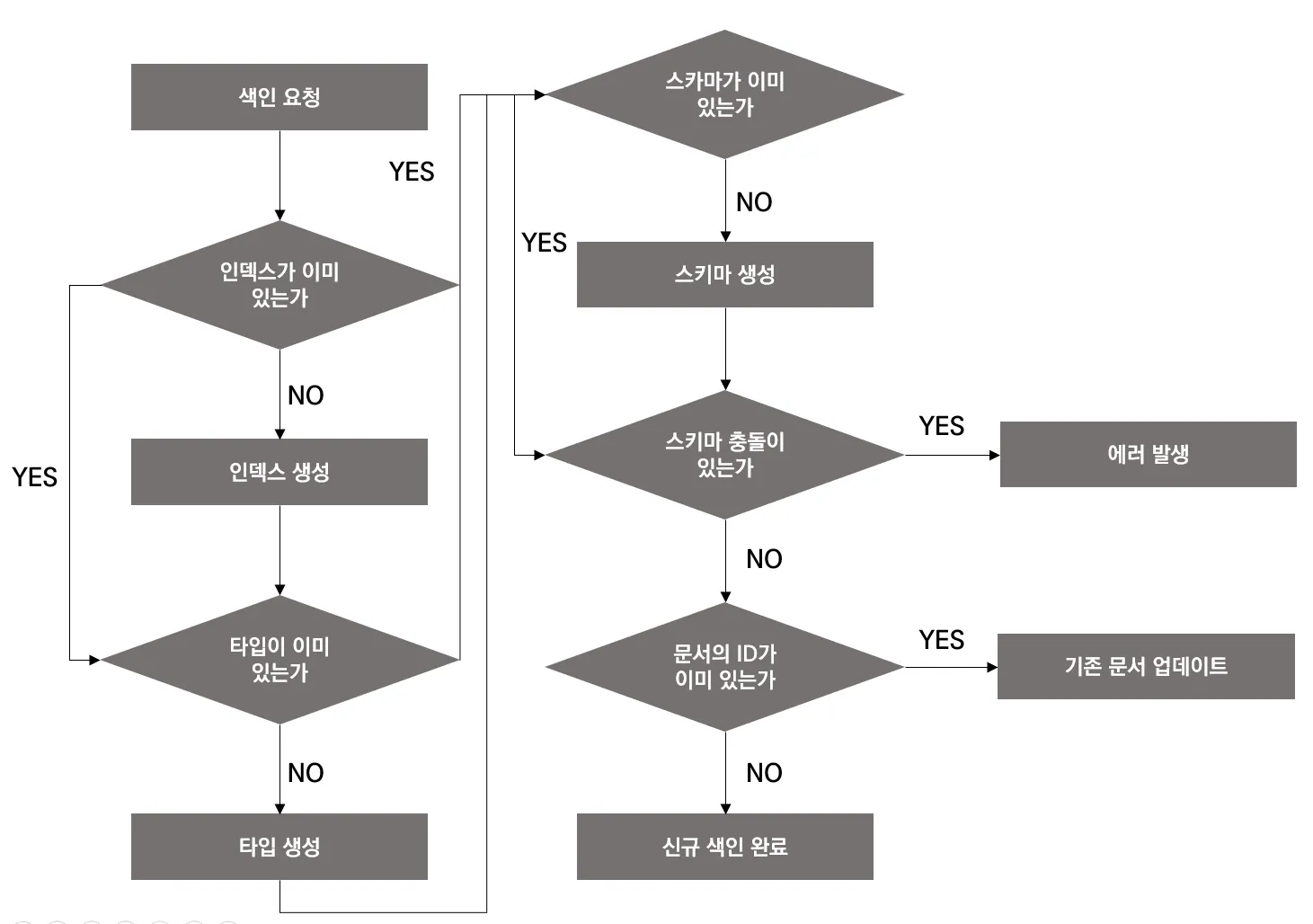
색인이 일어나는 과정
: 스키마 충돌은 기존에 숫자 형태로 정의된 필드에 문자 형태의 값이 들어오는 예시를 들 수 있다. 즉 타입이 기존의 형태와 맞지 않아서 발생하는 오류
GET
: 조회 시에는 해당 문서의 메타데이터가 함께 나오는데, 메타데이터에는 어떤 인덱스에 있는지(_index), 어떤 타입인지(_type), 문서의 아이디는 무엇인지(_id), 문서의 내용(source)에 포함된다.
DELETE
: 삭제 시, result의 상태값으로 연산에 대한 결과를 확인할 수 있다. 삭제 후 해당 문서를 조회하면 found항목이 false로 나온다.
다시 해보기
•
인덱스 생성 및 확인하기
> request
curl -X PUT "localhost:9200/contents?pretty"
> result
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "contents"
}
Shell
복사
> request
curl -s http://localhost:9200/_cat/indices?v
> result
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open contents a1 5 1 0 0 1.1kb 1.1kb
yellow open user a2 5 1 1 0 4.5kb 4.5kb
Shell
복사
•
문서 색인하기
> request
curl -X PUT "localhost:9200/contents/_doc/1?pretty" -H
'Content-Type: aplication/json' -d'
{
"title": "How to use ElasticSearch",
"author": "alden.kang"
}
> result
{
"_index" : "contents",
"_type" : "_doc",
"_id" : "1",
"_version": 1,
"result" : "created",
"_shards" : {
"_total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
Shell
복사
: 문서와 ID를 1로 색인했고 정상적으로 색인되었음을 알 수 있다. 특히 created라고 표현한 것을 기억해라, 문서의 내용을 바꾼 후 똑같이 입력하면 어떻게 되는지 보자.
•
문서 수정하기
> request
curl -X PUT "localhost:9200/contents/_doc/1?pretty" -H
'Content-Type: aplication/json' -d'
{
"title": "How to use ElasticSearch",
"author": "alden.kang, benjamin.butn"
}
> result
{
"_index" : "contents",
"_type" : "_doc",
"_id" : "1",
"_version": 2,1
"result" : "updated",
"_shards" : {
"_total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
Shell
복사
: 앞서 문서 색인하기 과정에서 나온 응답과 비슷하지만 _version 값과 result 값이 각각 1에서 2로, created에서 updated로 바뀌었다.
: 이처럼 동일한 ID로 문서를 색인하면 문서가 수정된다.
•
스키마 확인하기
{ ...
"author" : { ... }
"title" : { ...... }
}
Shell
복사
•
새로운 필드 색인하기
> request
curl -X PUT "localhost:9200/contents/_doc/1?pretty" -H
'Content-Type: aplication/json' -d'
{
"title": "How to use Nginx",
"author": "alden.kang, benjamin.butn"
"rating": 5.0
}
> result
{
"_index" : "contents",
"_type" : "_doc",
"_id" : "1",
"_version": 3
"result" : "created",
"_shards" : {
"_total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}
Shell
복사
: 기존에 있던 title과 author 필드 외에 rating 필드를 추가했고 정상적으로 색인되었다. 이후 스키마 정보를 보면 rating 필드가 동적으로 스키마에 추가된 것을 알 수 있다.
: 즉 새로운 필드가 축다ㅚ면 해당 필드가 색인되고 스키마도 추가로 정의된다는 것을 알 수 있다.
•
동적 스키마 변경
{ ...
"author" : { ... }
"rating" : { ... }
"title" : { ...... }
}
Shell
복사
: rating 필드는 실수형으로 입력되어 float 타입으로 정의되었다.
•
필드 충돌
> request
curl -X PUT "localhost:9200/contents/_doc/1?pretty" -H
'Content-Type: aplication/json' -d'
{
"title": "How to use Nginx",
"author": "alden.kang, benjamin.butn"
"rating": "N/A"
}
> result
{
"error" : {
"user_cause" : [
{
"_type" : "mapper_parsing_excepiton",
"reason" : "failed to prase field [rating] of type [float]"
}
],
"type": "mapper_parsing_excepiton",
"reason" : "created",
"caused_by" : {
"type" : "number_format_exception",
"reason" : "For input string: \"N/A\""
}
},
"status" : 400
}
Shell
복사
: rating 필드는 현재 실수형 타입으로 동적 스키마가 생성된 상태로 rating 필드에 “N/A” 값으로 색인을 시도했지만 타입이 불일치하여 실패했다.
2.2 문서 검색하기
•
먼저 json 파일을 사용해 10개의 데이터를 삽입
•
검색하기
◦
풀 스캔 쿼리
: 모든 데이터를 검색
curl -X GET “localhost:9200/books/_search?q=*&pretty”
Shell
복사
: q는 쿼리를 *는 모든 단어를 의미, 중요하게 봐야할 메타데이터는 took, _shard/total, hits/total로 각각 27 → 3ms 소요, 검색에 참여한 샤드의 갯수 5개, 검색 결과의 갯수 10개
◦
특정 문자가 포함된 문서를 검색
curl -X GET “localhost:9200/books/_search?q=elasticsearch&pretty”
Shell
복사
: 1개의 문서가 검색됨
◦
rating 기준으로 검색하기
curl -X GET “localhost:9200/books/_search?pretty” -H
'Content-Type: application/json' -d '
{
"query": {
"match": {
"rating": 5.0
}
}
}
'
Shell
복사
◦
범위 쿼리
: 필터와 쿼리는 조금 다른데, 쿼리가 문자열 안에 특정 문자가 포함되었는지 아닌지를 확인하는 과정이라면 필터는 예/아니오로 구분하는 방식
: 남자인지 여자인지를 찾기 위해서는 남자인가 아닌가 방식으로 검색을 시도하지만 서울에 사는 사람들을 찾기 위해서는 서울특별시라는 단어가 주소에 포함되어 있는지를 검색하는 것
2. 3 문서 분석하기
: 앞에서는 입력된 문서에 특정 문자가 들어있는지 검색하거나 특정 조건을 만족하는 문서를 검색했는데, ElasticSearch에서는 이런 검색 작업을 바탕으로 분석 작업도 할 수 있다.
: 예를 들어 서울에 살고 있는 사람이 몇 명인지, 아니면 특정 기술을 가지고 있는 사람이 몇 명인지 등의 통계를 작성하는 식으로 말이다.
: 이런 분석 작업을 aggregation이라고 부르며 역시 search API를 기반으로 진행된다.
◦
topics에 나오는 단어 빈도 찾기
curl -X GET “localhost:9200/books/_search?pretty” -H
'Content-Type: application/json' -d '
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "topics.keyword"
}
}
}
}
}
'
Shell
복사
: 위의 쿼리를 사용해 어떤 토픽이 가장 많이 사용되었는지를 확인할 수 있다.
◦
토픽별 평균 내기
curl -X GET “localhost:9200/books/_search?pretty” -H
'Content-Type: application/json' -d '
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "topics.keyword"
}
},
"aggs": {
"average_reviews": {
"avg": {
"field": "reviews"
}
}
}
}
}
}
'
Shell
복사
: 평균적으로 가장 많은 리뷰를 보유하고 있는 토픽을 확인할 수 있다. 이런 종류의 분석 역시 사용자의 트렌드를 분석하는 용도로 활용할 수 있다.
: 보통 분석 작업은 직접 쿼리를 생성하여 진행하기보다는 Kibana 혹은 Grafana와 같은 시각화 툴을 사용해서 진행한다.
: 로그를 수집한 후 로그의 총 개수를 세거나, 로그의 유형별 개수를 세는 용도로 활용할 수 있으며 분석 작업은 경우에 따라 매우 많은 양의 힙 메모리를 사용할 수 있으므로 시각화 툴을 사용해 분석할 때에는 데이터 시간 범위를 지나치게 크게 잡지 말자
: 3년 간, 이런 큰 범위의 데이터를 불러올 경우, 클러스터의 응답 불가 현상이 발생할 수 있다.
2. 4 마치며
1.
ElasticSearch는 JSON 형태의 문서를 색인, 조회, 검색, 분석할 수 있다.
2.
문서를 색인하기 위해 인덱스, 타입, 스키마 등을 미리 정의해둘 필요는 없다.
3.
이미 정의해놓은 스키마와 다른 형태의 데이터가 입력되면 에러가 발생하지만 해당 문서는 기본적으로 색인되지 않는다.
4.
쿼리를 이용해 문서를 검색할 수 있으며 aggregation이라고 부르는 분석을 통해 문서의 통계 작업을 진행할 수 있다.

