
•
6장에서 다루는 내용
◦
단위 테스트 스타일 비교
◦
함수형 아키텍처와 헥사고날 아키텍처의 관계
◦
출력 기반 테스트로 전환
•
이 장에서는 단위 테스트 스타일을 비교해본다.
◦
일반적으로 출력 기반이 가장 좋고 상태 기반는 두 번째로 좋은 선택이며 통신 기반은 간헐적으로만 사용해야 한다.
•
출력 기반 테스트 스타일은 순수 함수 방식으로 작성된 코드에만 적용할 수 있다. 이를 위해 함수형 프로그래밍 원칙을 이용해 기반 코드가 함수형 아키텍처를 지향하게끔 재구성해야 한다.
•
이 장을 마쳤을 때, 함수형 프로그래밍이 출력 기반 테스트와 어떻게 관련되어 있는지 이해할 수 있어야 한다.
•
또한 출력 기반 스타일을 사용해 테스트를 작성하는 방법뿐만 아니라 함수형 프로그래밍과 함수형 아키텍처가 지닌 한계도 배운다.
1. 단위 테스트의 세 가지 스타일
•
다음 세 스타일이 존재한다.
◦
출력 기반 테스트
◦
상태 기반 테스트
◦
통신 기반 테스트
1.
출력 기반 테스트 정의
•
테스트 대상 시스템에 입력을 넣고 생성되는 출력을 검증하는 방식이다.
•
이러한 단위 테스트 스타일은 전역 상태나 내부 상태를 변경하지 않는 즉 사이드 이펙트가 없고 코드에만 적용되므로 반환 값만 검증하면 된다.
◦
이는 함수형이라고도 한다. 이 이름은 사이드 이펙트 없는 코드 선호를 강조하는 프로그래밍 방식인 함수형 프로그래밍에 뿌리를 두고 있다.
•
다음 코드가 그 예시다.
public class PriceCalculator {
public double calculateDiscount(int price) {
return price * 0.99;
}
}
@Test
void test() {
// arrange
int price = 1000;
PriceCalculator sut = new PriceCalculator();
// action
double result = sut.normalizeNameLength(price);
// assert
assertThat(result).isEqualTo(price * 0.99);
}
Java
복사
2.
상태 기반 스타일의 정의
•
상태 기반 스타일은 작업이 완료된 후 시스템의 상태를 확인하는 것이다.
•
이 테스트 스타일에서 상태라는 용어는 SUT나 협력자 중 하나 또는 데이터베이스나 파일 시스템 등과 같은 프로세스 외부 의존성의 상태를 의미한다.
•
다음 코드가 그 예시다.
public class Shop {
public double addProduct(Product product) {
...
}
}
@Test
void test() {
// arrange
Product banana = new Banana();
Shop sut = new Shop();
// action
sut.addProduct(banana);
// assert
assertThat(sut.getProductCount()).isEqualTo(1);
}
Java
복사
3.
통신 기반 스타일의 정의
•
이 스타일은 목을 사용해 테스트 대상 시스템과 협력자 간의 통신을 검증한다.
•
다음 코드가 그 예시다.
public void sendGreetingEmail() {
// arrange
EmailSender emailSender = Mockito.mock(EmailSender.class);
UserService sut = new UserService(emailSender);
// action
sut.greetUser("test@test.test");
// assert
Mockito.verify(emailSender, Mockito.times(1)).send();
}
Java
복사
고전파는 통신 기반 스타일보다 상태 기반 스타일을 더 선호한다. 런던파는 이와 반대로 선택한다. 두 분파는 출력 기반 테스트를 사용한다.
2. 단위 테스트 스타일 비교
•
출력, 상태, 통신 기반 단위 테스트 스타일은 낯설지 않다. 이제 4장에서 학습한 좋은 단위 테스트의 4대 요소로 서로 비교해보겠다.
◦
회귀 방지, 리팩토링 내성, 빠른 피드백, 유지보수성
1.
회귀 방지, 피드백 속도 지표로 스타일 비교하기
•
회귀 방지
◦
실행되는 코드의 양이 많든 적든 테스트를 작성하기엔 용이하다. 코드 복잡도, 도메인 유의성도 마찬가지다.
◦
따라서 단위 테스트의 스타일은 회귀 방지 지표에 큰 영향을 끼치지 않는다.
•
피드백 속도
◦
피드백 속도 역시 관련이 없다.
◦
프로세스 외부 의존성과 충분히 떨어져서 테스트된다면 테스트 스타일은 거의 동일한 피드백 속도를 제공하기 때문이다.
2.
리팩토링 내성 지표로 스타일 비교하기
•
리팩토링 내성은 리팩토링 중에 발생하는 거짓 양성 수에 대한 척도다. 결국 식별할 수 있는 동작이 아닌 코드의 구현 세부 사항에 결합된 테스트의 결과다.
◦
출력 기반은 거짓 양성 방지가 가장 우수하다.
▪
테스트가 테스트 대상 메소드에만 결합되기 때문이다.
▪
이런 테스트가 구현 세부 사항에 결합하는 경우는 테스트 대상 메소드가 구현 세부 사항일 때 뿐이다.
◦
상태 기반은 일반적으로 거짓 양성을 유발하기 쉽다.
▪
이러한 테스트는 테스트 대상 메소드 외에도 클래스 상태와 함께 동작한다.
▪
테스트와 제품 코드 간의 결합도가 클수록 유출된 구현 세부 사항에 테스트가 얽매여있을 가능성이 더 높다.
▪
상태 기반 테스트는 API 노출 영역(getter 등)에 의존하므로 구현 세부 사항과 결합할 가능성도 더 높다.
◦
통신 기반은 거짓 양성에 가장 취약하다.
▪
테스트 더블로 상호 작용을 확인하는 테스트는 대부분 깨지기 쉽기 때문이다.
▪
이는 항상 스텁과 상호작용하는 경우로 이러한 상호 작용을 테스트해서는 안 된다. 스텁은 동작이 무언가를 하기위한 값을 제공만 해야한다.
▪
이것이 괜찮은 경우는 해당 애플리케이션에 접근할 수 있는 방법이 내부 로직뿐만이 아닐때다.
3.
유지 보수성 지표로 스타일 비교하기
•
유지 보수성 지표는 단위 테스트 스타일과 밀접한 관련이 있다. 더욱이 지표를 개선할 방법도 별로 많지 않다.
•
유지 보수성은 단위 테스트의 유지비를 측정하며 다음 두 가지 특성으로 정의한다.
◦
테스트를 이해하기에 얼마나 어려운가?
▪
테스트가 크면 필요할 때 이해하기도 변경하기도 어려우므로 유지 보수가 쉽지 않다.
◦
테스트를 실행하기에 얼마나 어려운가?
▪
마찬가지로 하나 이상의 프로세스 외부 의존성과 직접 작동하는 테스트는 데이터베이스 세팅, 네트워크 연결 등으로 운영할 때 비용이 발생한다.
•
출력 기반의 테스트 유지 보수성
◦
다른 두 가지 스타일에 비해 출력 기반 테스트가 가장 유지 보수하기 용이하다. 거의 짧고 간결하기 때문이다.
◦
이러한 이점은 메소드로 입력을 공급하는 것과 해당 출력을 검증하기 때문이다. 단 몇 줄로 이 두가지를 수행할 수 있다. 기억하자 일반적으로 코드는 짧을수록 이해하기 쉽다.
◦
출력 기반 테스트의 기반 코드는 전역 상태나 내부 상태를 변경할 리가 없으므로 프로세스 외부 의존성을 다루지 않는다. 따라서 실행하기도 쉽다.
•
상태 기반의 테스트 유지 보수성
◦
상태 기반 테스트는 일반적으로 출력 기반 테스트보다 유지 보수성이 떨어진다. 이는 상태 검증이 종종 출력 검증보다 더 많은 코드 라인을 필요로 하기 때문이다.
public void addCommentToArticle() {
// arange
Article sut = new Article();
String text = "Comment text";
String author = "John Doe";
DateTime now = new DateTime(2019, 4, 1);
// action
sut.AddComment(text, author, now);
// assert
Assert.Equal(1, sut.Comments.Count);
Assert.Equal(text, sut.Comments[0].Text);
Assert.Equal(author, sut.Comments[0].Author);
Assert.Equal(now, sut.Comments[0].DateCreated);
}
Java
복사
public void addCommentToArticle() {
// arange
Article sut = new Article();
String text = "Comment text";
String author = "John Doe";
DateTime now = new DateTime(2019, 4, 1);
// action
sut.AddComment(text, author, now);
// assert
sut.ShouldContainNumberOfComments(1).WithComment(text, author, now);
}
Java
복사
•
이처럼 헬퍼 메소드를 이용해서 문제를 완화할 수 있지만 이것도 비용이다.
◦
상태 기반 테스트를 단축하는 또 다른 방법으로 검증 대상 클래스의 동등 멤버를 정의해 비교할 수 있다.
▪
이는 강력한 기술이지만 본질적으로 클래스가 값에 해당하고 값 객체로 변환할 수 있을 때만 효과적이다. 그렇지 않으면 코드 오염으로 이어진다.
◦
보다시피 이 두 가지 기법은 양날의 검이므로 가끔만 적용할 수 있다. 그리고 이를 적용하더라도 상태 기반 테스트는 출력 기반 테스트보다 공간을 많이 차지하므로 유지 보수성이 떨어진다.
•
통신 기반의 테스트 유지 보수성
◦
통신 기반 테스트는 유지 보수성 지표에서 상태 기반 테스트보다도 낮다.
◦
통신 기반 테스트은 테스트 더블과 상호 작용 검증을 설정해야 하며 이는 공간을 많이 차지한다. 더불어 목이 사슬 형태로 있을 때 테스트는 더 커지고 유지 보수가 어려워진다.
4.
스타일 비교하기: 결론
•
비교 결과는 다음과 같다.
•
일반적으로 출력 기반 테스트가 좋은 단위 테스트의 특성을 만족한다.
◦
이 스타일은 구현 세부 사항과 거의 결합되지 않으므로 리팩토링 내성을 적절히 유지하고자 주의를 많이 기울일 필요가 없다.
◦
이러한 테스트는 간결하고 프로세스 외부 의존성이 없기 때문에 유지 보수도 쉽다.
출력 기반 | 상태 기반 | 통신 기반 | |
회귀 방지 | - | - | - |
피드백 속도 | - | - | - |
리팩토링 내성을 지키기 위한 노력 | 낮음 | 중간 | 중간 |
유지 비용 | 낮음 | 중간 | 높음 |
•
상태, 통신 기반 테스트는 두 지표 모두 좋지 않다. 공개 API면서 구현 세부 사항인 메소드에 결합할 가능성이 높고 크기도 커서 유지 비용이 많이 든다.
•
따라서 항상 출력 기반 테스트를 선호하라.
◦
하지만 출력 기반 테스트를 작성하기는 어렵다. 함수형으로 작성된 코드에만 적용할 수 있고 대부분의 객체지향 프로그래밍 언어에는 해당하지 않기 때문이다.
•
그럼에도 테스트를 출력 기반 테스트로 변경하는 기법이 있다. 코드를 순수 함수로 만들면 상태, 통신 기반 테스트 대신 출력 기반 테스트가 가능해진다.
3. 함수형 아키텍처 이해
•
이 절에서는 바꾸는 기법을 이해하기 위해 함수형 프로그래밍과 함수형 아키텍처가 무엇인지 알아보고 헥사고날 아키텍처와 어떤 관련이 있는지 알아본다.
1.
함수형 프로그래밍이란?
•
출력 기반은 함수형이라고도 한다. 기반 제품 코드를 함수형 프로그래밍을 이용해 순수 함수 방식으로 작성해야 하기 때문이다.
•
함수형 프로그래밍은 수학적 함수를 사용한 프로그래밍이다. 수학적 함수란 다음과 같은 특징을 가진다.
◦
수학적 함수는 숨은 입출력이 없는 함수다.
◦
수학적 함수의 모든 입출력은 메소드 시그니처에 명시해야 한다.
◦
수학적 함수는 호출 횟수에 상관없이 주어진 입력에 대해 동일한 출력을 생성하는 즉 멱등성을 유지해야 한다.
public double calculateDiscount(int price) {
return price * 0.99;
}
Java
복사
•
이 메소드는 하나의 입력과 하나의 출력이 있으며 둘 다 메소드 시그니처에 명시되어 있다. 이로써 calcuateDiscount()는 수학적 함수가 된다.
•
숨은 입출력이 없는 메소드는 수학에서 말하는 함수의 정의를 준수하기 때문에 수학적 함수라고 한다.
◦
수학에서의 함수는 x 집합의 각 요소에 대해 y 집합에서 정확히 하나의 요소를 찾는 두 집합 사이의 관계다.
•
입출력을 명시한 수학적 함수는 이에 따르는 테스트가 간결하며 이해하고 유지 보수하기 쉬우므로 테스트하기가 매우 쉽다.
•
출력 기반 테스트를 적용할 수 있는 메소드 유형은 수학적 함수뿐이다.
•
반면에 숨은 입출력은 코드를 테스트하기 어렵게 만든다. 숨은 입출력의 유형은 다음과 같다.
◦
사이드 이펙트 : 사이드 이펙트는 메소드 시그니처에 표시되지 않은 출력이며 따라서 숨어있다. 연산은 인스턴스의 상태를 변경하고 파일 시스템을 조작하는 등 사이드 이펙트를 발생시킨다.
◦
예외 : 메소드가 예외를 던지면 메소드 시그니처에 명시된 리턴 값을 우회하는 경로를 타게 된다. 호출된 예외는 호출 스택의 어느 곳에서도 발생하므로 메소드 시그니처가 전달하지 않는 출력을 추가한다.
◦
내외부 상태에 대한 참조 : DateTime.now()와 같이 static을 통해 날짜와 시간을 가져올 수도 있다. 데이터베이스에 질의할 수 있고 비공개 변경 가능 필드를 참조할 수도 있다. 모두 메소드 시그니처에 언급되지 않은 실행 흐름에 대한 입력이며 따라서 숨어있다.
•
메소드가 수학적 함수인지 판단하는 가장 좋은 방법은 프로그램의 동작을 변경하지 않고 해당 메소드에 대한 호출을 반환 값으로 대체할 수 있는지 확인하는 것이다.
◦
메소드 호출을 해당 값으로 바꾸는 것을 참조 투명성이라고 한다. 다음이 그 예다.
public int increment(int x) {
return x + 1;
}
Java
복사
▪
이 메소드는 수학적 함수다. 다음 두 구문이 서로 동일하기 때문이다.
int y = increment(4);
int y = 5;
Java
복사
◦
반면 다음은 수학적 함수가 아니다.
int x = 0;
public int increment(int x) {
x++;
return x;
}
Java
복사
▪
이 예제에서 숨은 출력 즉 사이드 이펙트는 필드 x 값의 변경이다.
◦
사이드 이펙트는 숨은 출력의 가장 일반적인 유형이다.
2.
함수형 아키텍처란?
•
결국 사이드 이펙트는 사용자 정보를 변경하거나 장바구니에 물건을 담는 등 모든 애플리케이션이 만들어내는 행위다.
•
함수형 프로그래밍의 목표는 사이드 이펙터를 완전히 제거하는 것이 아니라 비즈니스 로직을 처리하는 코드와 사이드 이펙트를 일으키는 코드를 분리하는 것이다.
◦
이 두 가지 책임은 각각을 놓고 보더라도 충분히 분리될만큼 복잡하다. 이 둘을 동시에 구현하고자 고려하게되면 복잡도가 배가되고 장기적으로 생산성을 저하시킨다.
•
함수형 아키텍처는 바로 이 곳에 사용된다. 사이드 이펙트를 비즈니스 연산 끝으로 몰아서 비즈니스 로직을 사이드 이펙트로부터 분리시킨다.
함수형 아키텍처는 사이드 이펙트를 다루는 코드를 최소화하면서 순수 함수 방식으로 작성한 코드의 양을 극대화시킨다. 일단 객체가 생성되면 그 상태를 변경시킬 수 없다.
•
다음 두 가지 코드 유형을 구분해서 비즈니스 로직과 사이드 이펙트를 분리할 수 있다.
◦
결정을 내리는 코드
▪
이 코드는 사이드 이펙트가 필요 없기 때문에 수학적 함수를 사용해 작성할 수 있다.
◦
해당 결정에 따라 작동하는 코드
▪
이 코드는 수학적 함수에 의해 이뤄진 결과를 데이터베이스의 변경이나 메시지 버스로 전송된 메시지와 같이 가시적인 부분으로 변환한다.
•
결정을 내리는 코드는 종종 함수형 코어라고도 한다. 해당 결정에 따라 작용하는 코드는 가변 셸이다. 함수형 코어와 가변 셰을 다음과 같은 방식으로 동작한다.
◦
가변 셸은 모든 입력을 수집한다.
◦
함수형 코어는 결정을 생성한다.
◦
셸은 결정을 사이드 이펙트로 변환한다.
•
이 두 계층을 지속적으로 잘 분리하려면 가변 셸이 의사결정을 수행하지 않게끔 결정을 나타내는 클래스에 정보가 충분히 있는지 확인해야 한다.
•
다시 말해 가변 셸은 가능한 아무 말도 하지 않아야 한다. 목표는 출력 기반 테스트로 함수형 코어를 두루 다루고 가변 셸을 훨씬 더 적은 수의 통합 테스트에 맡기는 것이다.
3.
함수형 아키텍처와 헥사고날 아키텍처 비교
•
둘은 비슷한 점이 많다. 둘 다 관심사 분리라는 아이디어를 기반으로 한다. 그러나 분리를 둘러싼 구체적인 내용은 다양하다.
◦
헥사고날 아키텍처는 도메인 계층과 애플리케이션 서비스 계층을 구별한다.
◦
도메인 계층은 비즈니스 로직에만 책임이 있는 반면, 애플리케이션 서비스 계층은 데이터베이스나 STMP와 같은 외부 애플리케이션과의 통신에 책임이 있다.
◦
이는 결정과 실행을 분리하는 함수형 아키텍처와 매우 유사하다.
•
또 다른 유사점은 의존성 간의 단방향 흐름이다.
◦
헥사고날 아키텍처에서 도메인 계층 내 클래스는 서로에게만 의존해야 한다. 애플리케이션 서비스 계층의 클래스에 의존해서는 안 된다.
◦
마찬가지로 함수형 아키텍처의 불변 코어는 가변 셸에 의존하지 않는다. 자급할 수 있고 외부 계층과 격리되어 동작할 수 있다. 이로 인해 함수형 아키텍처가 테스트하기 쉬운 것이다.
◦
가변 셸에서 불변 코어를 떼어내 셸이 제공하는 입력을 단순한 값으로 모방할 수 있다.
•
이 둘의 차이점은 사이드 이펙트에 대한 처리에 있다.
◦
함수형 아키텍처는 모든 사이드 이펙트를 불변 코어에서 비즈니스 연산 가장자리로 밀어낸다. 이 가장자리는 가변 셸이 처리한다.
◦
헥사고날 아키텍처는 도메인 계층에 제한하는 한, 도메인 계층으로 인한 사이드 이펙트도 문제없다. 모든 수정 사항은 도메인 계층 내에 있어야 하며 계층의 경계를 넘어서는 안 된다.
▪
도메인 계층의 인스턴스는 데이터베이스에 직접 저장할 수 없지만 상태는 변경할 수 있다. 애플리케이션 서비스 계층의 데이터베이스가 이를 적용한다.
함수형 아키텍처는 헥사고날 아키텍처의 하위 분류다. 극단적으로는 함수형 아키텍처를 헥사고날 아키텍처로 볼 수도 있다.
4. 함수형 아키텍처와 출력 기반 테스트로의 전환
•
이 절에서는 애플리케이션 샘플을 함수형 아키텍처로 리팩토링한다. 두 가지 리팩토링 단계를 나눌 수 있다.
◦
프로세스 외부 의존성에서 목으로 변경한다.
◦
목에서 함수형 아키텍처로 변경한다.
•
상태, 통신 기반 테스트를 출력 기반 테스트 스타일로 리팩토링할 것이다.
1.
감사 시스템 소개
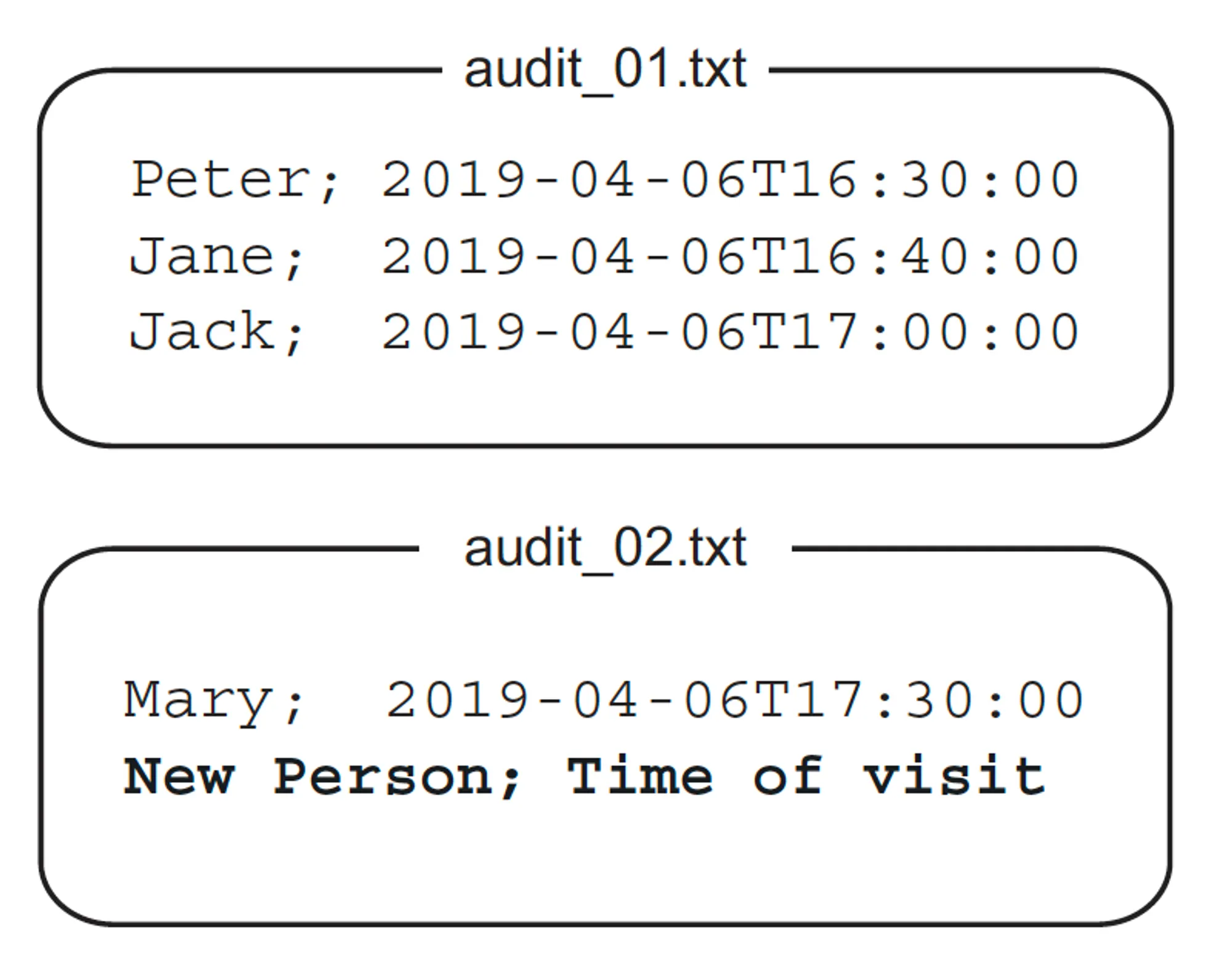
•
주 도메인은 조직의 모든 방문자를 추적하는 감사 시스템이다. 다음과 같은 구조로 텍스트 파일을 저장소로 사용한다.
•
이 시스템은 가장 최근 파일의 마지막 줄에 방문자의 이름과 방문 시간을 추가한다. 파일당 최대 항목 수에 도달하면 인덱스를 증가시켜 새 파일을 작성한다.
•
이 예제의 시스템 초기 버전은 다음과 같은 작업을 수행한다.
◦
작업 디렉토리에서 전체 파일 목록을 조회한다.
◦
인덱스별로 정렬한다.
◦
아직 파일이 존재하지 않으면 단일 레코드로 첫 번째 파일을 생성한다.
◦
감사 파일이 있으면 최신 파일을 가져와서 파일의 항목 수가 한계에 도달했는지에 따라 새 레코드를 추가하거나 새 파일을 생성한다.
⇒ 감이 온다.. 파일 시스템을 모킹해야할 것 같은..!
•
초기 버전의 AuditManager 클래스는 파일 시스템과 밀접하게 연결되어 있어 테스트하기가 매우 어렵다.
•
테스트 전에 파일을 세팅하고 테스트가 끝나면 해당 파일을 확인한 뒤 삭제해야 한다.
•
테스트에 있어서 파일 시스템은 병목 지점이 된다. 이는 테스트의 실행 흐름을 방해할 수 있는 공유 의존성이다.
•
초기 버전 테스트에 대한 단위 테스트 4대 요소를 정리해보면 다음과 같다.
초기 버전 | |
회귀 방지 | 좋음 |
리팩토링 내성 | 좋음 |
빠른 피드백 | 나쁨 |
유지 보수성 | 나쁨 |
•
물론 이는 단위 테스트의 정의에도 맞지 않다. 단위 테스트의 두, 세 번째 특성을 준수하지 않으므로 통합 테스트 범주에 속한다.
2.
테스트를 파일 시스템에서 분리하기 위한 목 사용
•
테스트가 영향을 받을 수 있는 공유 의존성에 결합된 문제는 일반적으로 해당 시스템을 목으로 처리해 해결한다.
•
파일의 모든 연산을 별도의 클래스(IFileSystem)으로 도출하고 AuditManager에 생성자로 해당 클래스를 주입할 수 있다.
•
이렇게 되면 AuditManager가 파일 시스템에서 분리되므로 공유 의존성이 사라지고 테스트를 서로 독립적으로 실행할 수 있다.
•
초기 버전보다 개선되었음을 확인할 수 있다. 테스트는 더이상 파일 시스템에 접근하지 않으므로 빠르게 실행된다. 또한 파일 시스템을 확인하고 삭제할 필요가 없으므로 유지 비용도 절감된다.
•
리팩토링을 진행했음에도 회귀 방지와 리팩토링 내성은 나빠지지 않았다.
초기 버전 | |
회귀 방지 | 좋음 |
리팩토링 내성 | 좋음 |
빠른 피드백 | 좋음 |
유지 보수성 | 중간 |
•
하지만 아직 개선할 점들이 보인다. 목을 사용했기에 목의 동작을 지정하는 복잡한 세팅이 사용되었다.
•
목 라이브러리가 열심히 목을해주고 있지만 평이한 입출력에 의존하는 테스트만큼 읽기가 쉽지 않다.
3.
함수형 아키텍처로 리팩토링하기
•
앞서 인터페이스 뒤로 사이드 이펙트를 숨기고 해당 인터페이스를 주입하는 대신 사이드 이펙트를 클래스 외부로 완전히 이동할 수 있다.
•
그러면 AuditManager는 파일에 수행할 작업을 둘러싼 결정만 책임지면 된다.
•
새로운 클래스인 Persister는 그 결정에 따라 파일 시스템에 업데이트를 적용한다.
•
여기서 Persister가 가변 셸 역할을 수행하며 AuditManager는 불변 코어에 해당한다.
•
이렇게 했을 때, 출력 기반 단위 테스트가 되어 좋은 단위 테스트 요소의 모든 부분이 좋아진다.
5. 함수형 아키텍처의 단점 이해하기
1.
함수형 아키텍처 적용 가능성
•
감사 시스템은 결정을 내리기 전에 입력을 모두 미리 수집할 수 있으므로 함수형 아키텍처에 적합했다.
•
의사 결정 절차의 중간 결과에 따라 프로세스 외부 의존성에서 추가 데이터를 질의가 필요할 수도 있다.
•
지난 24시간의 방문 횟수가 임계치를 초과했따면 감사 시스템이 방문자의 접근 레벨을 확인한다고 해보자. 이때 접근 레벨은 모두 데이터베이스에 저장되어 있다.
•
이런 상황에선 두 가지 해결책이 있다.
◦
애플리케이션 서비스 전면에서 디렉토리 내용과 더불어 방문자 접근 레벨을 수집해온다.
◦
AuditManager에서는 IsAccessLevelCheckRequired()와 같은 새로운 메소드를 둔다.
▪
애플리케이션 서비스에서 addRecord() 이전에 이 메소드를 호출하고 true를 반환하면 서비스는 접근 레벨을 가져온 후 addRecord()에 인수로 전달한다.
•
두 방법 모두 단점이 있다.
◦
첫 번째는 성능이 저하된다. 접근 레벨이 필요 없더라도 무조건 조회해야하기 때문이다. 그러나 비즈니스 로직과 외부 시스템과의 통신을 완전히 계속 분리할 수 있다.
◦
두 번째 방법은 성능 향상을 위해 분리를 다소 완화한다. 다만 데이터베이스를 호출할지에 대한 결정을 AuditManager가 아닌 애플리케이션 서비스가 처리한다.
2.
성능 단점
•
함수형 아키텍처와 전통적인 아키텍처 사이의 선택은 성능과 코드 유지 보수성(프로덕션 코드, 테스트 코드 모두) 간의 절충이다.
•
성능 영향이 적은 일부 시스템에서는 함수형 아키텍처를 사용해 유지 보수성을 향상시키는 편이 좋다. 물론 반대로 선택해야 하는 경우도 있다. 즉, 은탄환은 없다.
3.
코드베이스 크기 증가
•
코드베이스의 크기도 마찬가지다. 함수형 아키텍처는 불변 코어와 가변 셸 사이를 명확하게 분리해야 한다, 따라서 궁극적으로 코드 복잡도가 낮아지고 유지 보수성이 향상되지만 그 양이 늘어난다.
•
모든 도메인 모델이 초기 투자 비용이 높은 것이 타당할만큼 복잡도가 높은 것은 아니다. 항상 시스템의 복잡도와 중요성을 고려해 함수형 아키텍처를 전략적으로 적용하라.
•
대부분의 프로젝트에서는 모든 도메인 모델을 불변으로 할 수 없기에 출력 기반 테스트만 사용할 수 없다. 대부분의 경우, 출력 기반과 상태 기반을 조합하게 되며 통신 기반을 약간 섞어도 괜찮다.
•
이 장의 목표는 모든 테스트를 출력 기반 스타일로 전환하는 것이 아니라 가능한 많은 테스트를 전환하는 것이다.
요약
•
출력 기반 테스트는 SUT에 입력을 주고 출력을 확인하는 테스트 스타일이다. 이 테스트 스타일은 숨은 입출력이 없다고 가정하고 SUT 작업의 결과는 반환하는 값뿐이다.
•
상태 기반 테스트는 작업이 완료된 후의 시스템 상태를 확인한다.
•
통신 기반 테스트는 목을 사용해서 테스트 대상 시스템과 협력자 간의 통신을 검증한다.
•
단위 테스트의 고전파는 통신 기반 스타일보다 상태 기반 스타일을 선호한다. 런던파는 반대를 선호한다. 두 분파 모두 출력 기반 테스트를 사용한다.
•
출력 기반 테스트가 테스트 품질이 가장 좋다.
◦
이러한 테스트는 구현 세부 사항에 거의 결합되지 않으므로 리팩토링 내성이 있다. 또한 작고 간결하므로 유지 보수성도 좋다.
•
상태 기반 테스트는 안정성을 위해 더 신중해야 한다.
◦
단위 테스트를 하려면 비공개 상태를 노출하지 않도록 해야 한다.
◦
출력 기반 테스트보다 크기가 큰편이므로 유지 보수가 쉽지않다. 헬퍼 메소드와 값 객체를 사용해 유지 보수성을 향상시킬 수 있지만 완전히 제거할 수는 없다.
•
통신 기반 테스트도 안정성을 위해 더 신중해야 한다.
◦
애플리케이션 경계를 넘어서 외부 환경에 사이드 이펙트가 보이는 통신만 확인해야 한다.
◦
통신 기반 테스트의 유지 보수성은 출력 및 상태 기반 테스트와 비교할 때 좋지 않다.
◦
목은 공간을 많이 차지하는 경향이 있어서 가독성이 떨어진다.
•
함수형 프로그래밍은 수학적 함수로 된 프로그래밍이다.
◦
수학적 함수는 숨은 입출력이 없는 메소드다. 사이드 이펙트와 예외가 숨은 출력에 해당한다.
◦
내부 상태 또는 외부 상태에 대한 참조는 숨은 입력이다.
◦
수학적 함수는 명시적이므로 테스트 용이성을 향상시킨다.
•
함수형 프로그래밍의 목표는 비즈니스 로직과 사이드 이펙트를 분리시키는 것이다.
•
함수형 아키텍처는 사이드 이펙트를 비즈니스 연산의 가장자리로 밀어내 분리를 이루는 데 도움이 된다.
◦
이 방법으로 사이드 이펙트를 다루는 코드를 최소화하면서 순수 함수 방식으로 작성된 코드의 양을 최대화할 수 있다.
•
함수형 아키텍처는 모든 코드를 불변 코어와 가변 셸이라는 두 가지 범주로 나눈다.
◦
가변 셸은 입력 데이터를 불변 코어에 제공하고 코어가 내린 결정은 사이드 이펙트로 변환한다.
•
함수형 아키텍처와 헥사고날 아키텍처의 차이는 사이드 이펙트의 처리에 있다.
◦
함수형 아키텍처는 모든 사이드 이펙트를 도메인 계층 밖으로 밀어낸다.
◦
헥사고날 아키텍처는 도메인 계층에만 한정되어있다면 도메인 계층에 의해 만들어진 사이드 이펙트도 괜찮다.
•
함수형 아키텍처와 전통적인 아키텍처 사이의 선택은 성능과 코드 유지 보수성 사이의 절충이며 함수형 아키텍처는 유지 보수성 향상을 위해 성능을 희생한다.
•
모든 코드베이스를 함수형 아키텍처로 바꿀수는 없다.
◦
함수형 아키텍처를 전략적으로 적용하라.
◦
시스템의 복잡도와 중요성을 고려하라.
◦
코드베이스가 단순하거나 그렇게 중요하지 않으면 함수형 아키텍처는 별 효과가 없다.

