

•
가장 의미가 잘 전달되지 못한 원칙
: 단 하나의 일만 해야 한다는 원칙은 사실 따로 있다. 그것은 바로 함수는 반드시 하나의 단 하나의 일만 해야 한다는 원칙
⇒ 커다란 함수를 작은 함수들로 리팩터링하는 더 저수준에서 사용됨
: 단일 모듈의 변경의 이유가 하나, 오직 하나 뿐이어야 함
: 소프트웨어 시스템은 사용자와 이해관계자를 만족시키기 위해 변경됨
⇒ 하나의 모듈은 하나의 오직 하나의 사용자 또는 이해관계자에 대해서만 책임을 가짐
예시1. 우발적 중복
: 급여 애플리케이션의 Employee 클래스가 세 가지 메서드 calculatePay(), reportHours(), save()를 가질 때
⇒ calculatePay()는 회계팀에서 기능을 정의
⇒ reportHours()는 인사팀에서 기능을 정의
⇒ save()는 데이터베이스 관리자가 기능을 정의
: 이 세 메서드를 Employee라는 단일 클래스에 배치하여 회계팀, 인사팀, 데이터베이스 관리자라는 세 액터가 결합되어 버렸음
⇒ 이 결합으로 인해 인사팀의 결정에 대한 영향이 회계, 데이터베이스 관리자에 갈 수 있다.
: calculatePay()와 reportHours()가 초과 근무를 제외한 업무 시간을 계산하는 알고리즘을 공유한다고 할 때
: 코드 중복을 피하기 위해 regularHours()라는 메서드를 넣었을 때, 인사팀에서 이를 계산하는 방법을 변경했을 때 회계팀에 영향이 갈 수 있다.
예시2. 병합
: 소스 파일에 다양하고 많은 메서드를 포함하면 병합이 자주 발생할 가능성이 높아진다. 특히 이 메서드들이 서로 다른 액터들을 책임진다면 병합이 발생할 가능성은 높아진다.
⇒ DBA가 속한 CTO 팀에서 데이터베이스의 Employee 테이블 스키마를 약간 수정하기로 결정했을때,
⇒ 이와 동시에 인사 담당자가 속한 COO 팀에서 reportHours() 메서드의 보고서 포맷을 변경하기로 결정한다면
: 두 명의 서로 다른 개발자가 동시에 Employee 클래스를 체크아웃받은 후 변경사항을 적용시킬 것이다. 이 경우 두 변경사항은 충돌할 것이다.
해결책
: 이 문제의 해결책은 다양한데, 그 모두가 메서드를 각기 다른 클래스로 이동하는 방법이다. 가장 확실한 해결책은 데이터와 메서드를 분리하는 방식
: 즉 아무런 메서드가 없는 간단한 데이터 구조인 EmployeeData 클래스를 만들어 세 개의 클래스가 공유할 수 있도록 한다.
: 각 클래스는 자신의 메서드에 반드시 필요한 소스 코드만을 포함하고 세 클래스는 서로의 존재를 몰라야 한다.
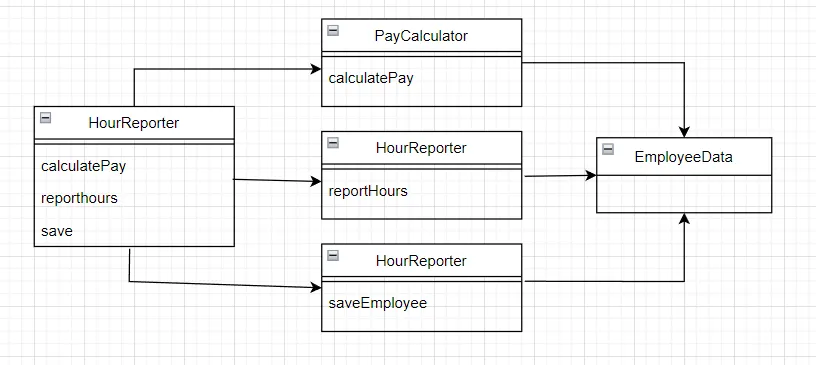
: 이 해결책은 개발자가 세 가지 클래스를 인스턴스화하고 이를 추적해야 한다는 것이 단점, 이를 간단히 해결하는 기법으로 퍼사드 패턴이 존재
⇒ EmployeeFacade에 코드는 거의 없음, 이 클래스는 세 클래스의 객체를 생성하고 요청된 메서드를 가지는 객체로 위임하는 일을 책임짐 ( 인터페이스? )
: 이 경우 가장 중요한 메서드는 기존의 Employee 클래스에 그대로 유지하되 Employee 클래스를 덜 중요한 나머짐 메서드들에 대한 퍼사드로 상요할 수도 있다.
: 여러 메서드가 하나의 가족을 이루고 메서드의 가족을 포함하는 각 클래스는 하나의 유효범위가 된다. 해당 유효 범위 밖에서는 이 가족에게 private 멤버가 있는지 알수없다.
결론
: 단일 책임 원칙은 메서드와 클래스 수준의 원칙, 하지만 이보다 상위의 두 수준에서도 다른 형태로 재등장, 컴포넌트 수준에서는 공통, 폐쇄 원칙,
: 아키텍처 수준에서는 아키텍처 경계의 생성을 책임지는 변경의 축이 된다.

