
1. 트랜잭션과 락
1. 트랜잭션과 격리 수준
•
트랜잭션은 ACID라 하는 원자성, 일관성, 격리성, 지속성을 보장해야 한다.
•
트랜잭션은 원자성, 일관성, 지속성을 보장하나 격리성을 완벽히 보장하려면 동시청 처리 성능이 매우 나빠지기 때문에 격리 수준을 두어 수행한다.
2. 낙관적 락과 비관적 락 기초
•
JPA의 영속성 컨텍스트를 적절히 활용하면 데이터베이스가 READ COMMITTED여도 어플리케이션 수준에서 REPEATABLE READ가 가능하다.
•
JPA는 데이터베이스 트랜잭션 격리 수준을 READ COMMITTED 정도로 가정하며 만약 일부 로직에 더 높은 격리 수준이 필요하다면 낙관적 락과 비관적 락 중 하나를 사용하면 된다.
◦
만약 사용자 A와 B가 같은 객체를 시간 차를 두고 갱신하면 나중에 수정한 사람의 것만 남게 될 것이다. 이를 두 번의 갱신 분실 문제라 한다.
◦
이를 해결하기 위해 마지막 커밋만 인정하기, 최초 커밋만 인정하기, 충돌하는 갱신 내용 병합하기 등의 방법이 있다.
3. @Version
•
JPA가 제공하는 낙관적 락을 사용하려면 @Version 어노테이션을 사용해서 버전 관리 기능을 추가해야 한다.
◦
버전 정보를 사용하면 최초 커밋만 인정하기가 적용되며 적용 가능한 타입은 Long(long), Integer(int), Short(short), Timestamp가 있다.
•
엔티티에 버전 관리용 필드를 하나 추가하고 @Version 어노테이션을 붙여두면 된다. 버전은 엔티티의 값을 변경하면 하나씩 자동으로 증가한다.
•
엔티티 수정 시, 조회 시점의 버전과 수정 시점의 버전이 다르면 예외가 발생한다. 따라서 최초 커밋만 인정하기가 적용된다.
•
JPA가 버전 비교를 수행하는 방법은 단순한데, 엔티티를 수정하고 트랜잭션을 커밋하면 영속성 컨텍스트를 플러쉬하면서 WHERE 절에 엔티티의 버전 정보를 추가한다.
4. JPA 락 사용
•
JPA는 다양한 락을 제공하며 조회하면서 락을 걸수도 필요할 때 락을 걸 수도 있다.
•
락은 다음 위치에 걸 수 있다.
◦
EntityManager.lock(), EntityManager.find(), EntityManager.refresh()
◦
Query.setLockMode()
◦
@NamedQuery
•
JPA가 제공하는 락 옵션은 javax.persistence.LockModeType에 정의되어 있다.
5. JPA 낙관적 락
•
낙관적 락은 버전을 사용한다. 따라서 낙관적 락을 사용하려면 버전이 있어야 한다. 낙관적 락은 트랜잭션을 커밋하는 시점에 충돌을 알 수 있다는 특징이 있다.
⇒ JPA 사용 시 추천하는 전략은 READ COMMITTED 트랜잭션 격리 수준과 낙관적 버전 관리를 사용하는 것이다.
•
락 옵션 없이 @Version만 있어도 낙관적 락이 적용되며 락 옵션을 사용하면 락을 더 세밀하게 사용할 수 있다.
◦
NONE: 락 옵션을 적용하지 않아도 @Version이 적용된 필드가 있으면 자동으로 낙관적 락이 적용될 때 옵션이다.
▪
용도: 조회한 엔티티를 수정할 때 다른 트랜잭션에 의해 변경되지 않아야 한다.
▪
동작: 엔티티를 수정할 때 버전을 체크하면서 버전을 증가시킨다. 이대 데이터베이스의 버전 값이 현재 객체의 버전과 다르면 예외가 발생한다.
▪
이점: 두 번의 갱실 분실 문제를 예방한다.
◦
OPTIMISTIC: 엔티티를 수정해야 버전을 체크하지만 이 옵션을 사용하면 엔티티를 조회만 해도 버전을 체크한다. 한 번 조회한 엔티티는 트랜잭션을 종료할 때까지 변경되지 않음을 보장한다.
▪
용도: 조회한 엔티티는 트랜잭션이 종료될 때까지 다른 트랜잭션에 의해 변경되지 않음을 보장한다.
▪
동작: 트랜잭션 커밋 시, 버전 정보를 조회하여 현재 엔티티의 버전과 같은지 검증한다. 만약 같지 않으면 예외가 발생한다.
▪
이점: OPTIMISTIC 옵션은 DIRTY READ와 NON-REPEATABLE READ를 방지한다.
⇒ 그럼 격리 수준이 어플리케이션 단에서 REAPETABLE READ 수준으로 설정되는 건가?
◦
OPTIMISTIC_FORCE_INCREMENT: 낙관적 락을 사용하면서 버전 정보를 강제로 증가한다.
▪
용도: 논리적인 단위의 엔티티 묶음을 관리할 수 있다. 즉 연관관계에 있는 객체 중 하나라도 변경되면 버전을 증가시킨다.
▪
동작: 엔티티를 수정하지 않아도 트랜잭션을 커밋할 때 UPDATE 쿼리를 사용해 버전 정보를 강제로 증가시킨다. 추가로 엔티티를 수정하면 버전 UPDATE가 또 발생한다. 총 2번 발생할 가능성이 있다.
▪
이점: 강제로 버전을 증가해서 논맂거인 단위의 엔티티 묶음을 버전 관리할 수 있다.
6. JPA 비관적 락
•
JPA가 제공하는 비관적 락은 데이터베이스 트랜잭션 락 메커니즘에 의존하는 방법이다. 주로 PERSSIMISTIC_WRITE 모드를 사용한다.
•
비관적 락은 다음과 같은 특징을 가진다.
◦
엔티티가 아닌 스칼라 타입을 조회하는 경우에도 사용할 수 있다.
◦
데이터를 수정하는 즉시 트랜잭션 충돌을 감지할 수 있다.
•
PERSSIMISTIC_WRITE: 비관적 락의 대표적인 옵션으로 데이터베이스에 쓰기 락을 걸 때 사용한다.
◦
용도: 데이터베이스에 쓰기 락을 건다.
◦
동작: select for update를 사용해서 락을 건다.
◦
이점: NON-REPEATABLE READ를 방지한다. 락이 걸린 로우는 다른 트랜잭션이 수정할 수 없다.
•
PERSSIMISTIC_READ: 데이터를 읽기 전용으로 락을 걸 때 사용한다. 일반적으로 잘 사용하지 않는다.
◦
MySQl: lock in share mode
◦
PostgreSQL: for share
•
PERSSIMISTIC_FORCE_INCREMENT: 비관적 락 중 유일하게 버전 정보를 사용한다. 비관적 락이지만 버전 정보를 강제로 증가시킨다.
7. 비관적 락과 타임아웃
•
비관적 락을 사용하면 락을 획득할 때까지 트랜잭션이 대기한다. 무한정 기다릴 수 없으므로 타임아웃 시간을 줄일 수 있다.
2. 2차 캐시
•
JPA가 제공하는 애플리케이션의 범위의 캐시에 대해 알아보고 하이버네이트와 EHCACHE를 사용해서 실제 캐시를 적용해본다.
1. 1차 캐시와 2차 캐시
•
데이터베이스에 접근하는 과정에서 사용하는 네트워크 비용은 어플리케이션 서버에서 내부 메모리에 접근하는 시간 비용보다 수만에서 수십만 배 이상 비싸다.
◦
따라서 조회한 데이터를 메모리에 캐시해두고 데이터베이스의 접근 횟수를 줄이면 어플리케이션 성능을 획기적으로 개선할 수 있다.
•
영속성 컨텍스트 내부에는 엔티티를 보관하는 저장소가 있는데 이것을 1차 캐시라고 하며 일반적인 웹 어플리케이션 환경은 트랜잭션을 시작하고 종료할 때까지만 1차 캐시가 유효하다.
◦
어플리케이션 전체로 보면 데이터베이스 접근 횟수를 획기적으로 줄이지는 못한다.
•
하이버네이트를 포함한 대부분의 JPA 구현체들은 어플리케이션 범위의 캐시를 지원하는데 이것을 공유 캐시 또는 2차 캐시라고 한다.
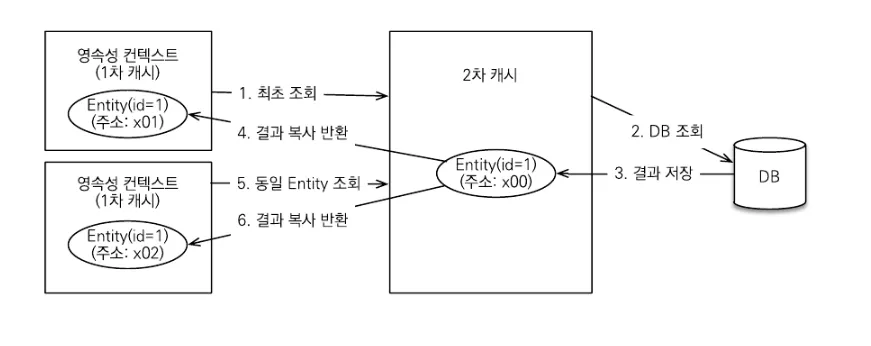
•
1차 캐시
◦
1차 캐시는 영속성 컨텍스트 내부에 있는데, 엔티티 매니저로 조회하거나 변경하는 모든 엔티티는 1차 캐시에 저장된다. 트랜잭션을 커밋하거나 플러시를 호출하면 1차 캐시에 있는 엔티티의 변경 내역을 동기화한다.
◦
JPA를 스프링 프레임워크나 J2EE와 같은 컨테이너 위에서 실행하면 트랜잭션을 시작할 때 영속성 컨텍스트를 생성하고 트랜잭션을 종료할 때 영속성 컨텍스트도 종료한다.
⇒ 물론 OSIV를 사용하면 영속성 컨텍스트의 생명주기를 요청의 생명주기와 함께 한다.
◦
1차 캐시는 끄고 켤 수 있는 오볏닝 아니며 영속성 컨텍스트 자체가 사실상 1차 캐시다.
•
2차 캐시
◦
어플리케이션에서 공유하는 캐시를 JPA는 공유 캐시라 하는데, 일반적으로 2차 캐시라고도 부른다.
◦
2차 캐시는 어플리케시연 범위의 캐시로 애플리케이션이 종료될 때까지 캐시가 유지된다. 분산 캐시나 클러스터링 환경의 캐시는 어플리케이션보다 더 오래 유지될 수도 있다.
◦
2차 캐시를 적용하면 JPA는 엔티티 매니저를 통해 데이터를 조회할 때 우선 2차 캐시에서 찾고 없으면 데이터베이스에서 찾는다.
⇒ 따라서 2차 캐시를 적절히 활용하면 데이터베이스 조회 횟수를 획기적으로 줄일 수 있다.
◦
2차 캐시의 특징은 다음과 같다.
▪
2차 캐시는 영속성 유닛 범위의 캐시다.
▪
2차 캐시는 조회한 객체를 그대로 반환하는 것이 아니라 복사본을 만들어서 반환한다.
▪
2차 캐시는 데이터베이스 기본 키를 기준으로 캐시하지만 영속성 컨텍스트가 다르면 객체 동일성을 보장하지 않는다.
2. JPA 2차 캐시 기능
•
JPA 2.0에서 2차 캐시 표준을 정의했다.
•
캐시 모드 설정
◦
2차 캐시를 사용하려면 엔티티에 javax.persistence.Cacheable 어노테이션을 사용하면 된다.
◦
persistence.xml에 shared-cache-mode를 설정하여 어플리케이션 전체에 캐시를 어떻게 적용할지 옵션을 설정할 수 있다.
◦
캐시 모드는 javax.persistence.SharedCacheMode에 정의되어 있는데 보통 ENALBE_SELECTIVE를 사용한다.
•
캐시 조회, 저장 방식 결정
◦
캐시를 무시하고 데이터베이스를 직접 조회하거나 캐시를 갱신하려면 캐시 조회 모드와 캐시 보관 모드를 사용하면 된다.
◦
캐시 조회 모드나 보관 모드에 따라 사용하는 프로퍼티와 옵션이 다르다.
▪
각각 retrieveMode, storeMode 이름이다.
•
JPA 캐시 관리 API
◦
JPA는 캐시를 관리하기 위한 javax.persistence.Cache 인터페이스를 제공하는데, 이는 EntityManagerFactory에서 획득할 수 있다.
3. 하이버네이트와 EHCACHE 적용
•
하이버네이트와 EHCACHE를 사용하여 2차 캐시를 적용할 수 있다.
◦
엔티티 캐시: 엔티티 단위로 캐시한다. 식별자로 엔티티를 조회하거나 컬렉션이 아닌 연관된 엔티티를 로딩할 때 사용한다.
◦
컬렉션 캐시: 엔티티와 연관된 컬렉션을 캐시한다. 컬렉션이 엔티티를 담고 있으면 식별자 값만 캐시한다.
◦
쿼리 캐시: 쿼리와 파라미터 정보를 키로 사용해서 캐시한다. 결과가 엔티티면 식별자 값만 캐시한다.
•
환경설정
◦
하이버네이트에서 EHCACHE를 사용하려면 hibernate-ehcache 라이브러리를 추가하면 된다.
•
쿼리 캐시와 컬렉션 캐시의 주의점
◦
엔티티 캐시를 사용해서 엔티티를 캐시하면 엔티티 정보를 모두 캐시하지만 쿼리 캐시와 컬렉션 캐시는 결과 집합의 식별자 값만 캐시한다.
◦
그리고 이 식별자 값을 하나씩 엔티티 캐시에서 조회해서 실제 엔티티를 찾는다.
3. 정리
•
트랜잭션의 격리 수준은 4단계가 있으며 격리 수준이 낮을수록 동시성은 증가하지만 격리 수준에 따른 문제가 발생한다.
•
영속성 컨텍스트는 데이터베이스 트랜잭션이 READ COMMITTED 격리 수준이어도 어플리케이션 레벨에서 REPEATABLE READ를 제공한다.
•
JPA는 낙관적 락과 비관적 락을 지원한다. 낙관적 락은 어플리케이션이 지원하는 락이고 비관적 락인 데이터베이스 트랜잭션 락 메커니즘을 따른다.
•
2차 캐시를 사용하면 어플리케이션의 조회 성능을 극적으로 올릴 수 있다.

