

: MySQL 쿼리를 작성하고 튜닝할 때 필요한 기본적인 MySQL 엔진의 기본 구조
1. MySQL의 전체 구조
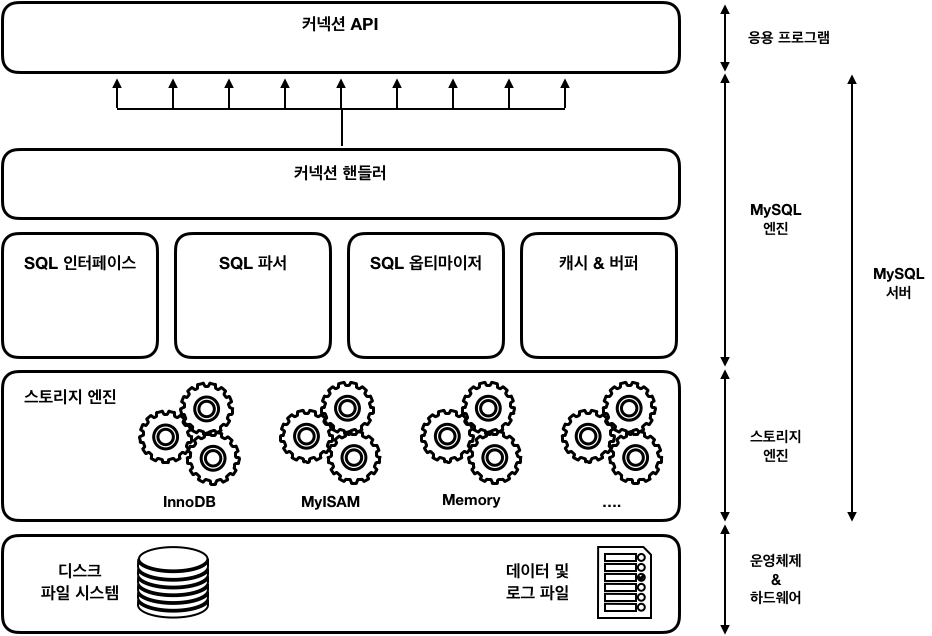
: MySQL은 일반 상용 RDBMS와 같이 대부분의 프로그래밍 언어로부터 접근 방법을 모두 지원
: MySQL 서버는 크게 MySQL 엔진과 스토리지 엔진으로 구분
1.
MySQL 엔진
: MySQL 엔진은 클라이언트로부터의 접속 및 쿼리 요청을 처리하는 커넥션 핸들러와 SQL 파서 및 전처리기, 쿼리의 최적화된 실행을 위한 옵티마이저가 존재
: MySQL은 표준 SQL(ANSI SQL) 문법을 지원하기 때문에 호환성이 높다.
2.
스토리지 엔진
: 실제 데이터를 디스크 스토리지에 저장하거나 디스크 스토리지로부터 데이터를 읽어오는 부분은 스토리지 엔진이 전담
: MySQL 서버에서 MySQL 엔진은 하나지만 스토리지 엔진은 여러 개를 동시에 사용할 수 있음
: CREATE TABLE test_table (fd1 INT, fd2 INT) ENGINE=INNODB;와 같이 실행하면 이후 해당 테이블의 모든 읽기 작업이나 변경 작업은 정의된 스토리지 엔진이 담당
: 각 스토리지 엔진은 성능 향상을 위해 키 캐시(MyISAM 스토리지 엔진)나 InnoDB 버퍼 풀(InnoDB 스토리지 엔진)과 같은 기능을 내장
3.
핸들러 API
: MySQL 엔진의 쿼리 실행기에서 데이터를 쓰거나 읽어야할 때는 각 스토리지 엔진에 쓰기 또는 읽기를 요청, 이러한 요청을 핸들러 요청, 여기서 사용되는 API를 핸들러 API라 함
: InnoDB 스토리지 엔진 또한 이 핸들러 API를 통해 MySQL 엔진과 데이터를 주고 받는데, 얼마나 많은 작업이 있었늕지 SHOW GLOBAL STATUS LIKE 'Handler%'로 확인할 수 있다.
2. MySQL 스레딩 구조
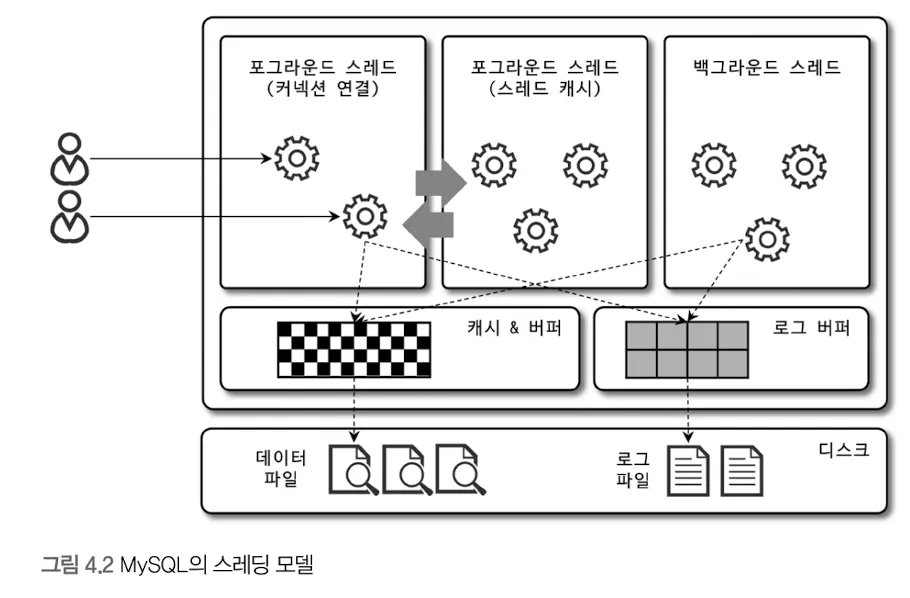
: MySQL 서버는 프로세스 기반이 아닌 스레드 기반으로 작동하며 크게 포그라운드 스레드와 백그라운드 스레드로 구분할 수 있다.
1.
포그라운드 스레드(클라이언트 스레드)
: 포그라운드 스레드는 최소한 MySQL 서버에 접속된 클라이언트의 수만큼 존재, 주로 각 클라이언트 사용자가 요청하는 쿼리 문장을 처리
: 클라이언트 사용자가 작업을 마치고 커넥션을 종료하면 포그라운드 스레드(스레드 캐시)로 돌아감, 이때 일정 수 이상 스레드 캐시에 존재하면 돌아가지 않고 종료시켜 수를 유지
: MySQL의 데이터를 데이터 버퍼나 캐시로부터 가져오며 없는 경우, 직접 디스크의 데이터나 인덱스 파일로부터 데이터를 읽어와서 작업을 처리
: MyISAM 테이블은 디스크 쓰기 작업까지 포그라운드가 처리, InnoDB 테이블은 데이터 버퍼나 캐시까지만 포그라운드 스레드가 처리하고 나머지는 백그라운드 스레드가 처리
2.
백그라운드 스레드
: MyISAM의 경우 해당사항이 별로 없는 부분이지만 InnoDB는 다음과 같은 작업들을 백그라운드 스레드에서 처리
•
인서트 버퍼를 병합하는 스레드
•
로그를 디스크로 기록하는 스레드
•
InnoDB 버퍼 풀의 데이터를 디스크에 기록하는 스레드
•
데이터를 버퍼로 읽어오는 스레드
•
잠금이나 데드락을 모니터링하는 스레드
: MyISAM의 경우, 쓰기 작업을 동기식으로 처리, InnoDB는 비동기적으로 처리하여 데이터 파일로 완전히 저장될때까지 기다리지 않아도 됨
프로세스 기반 db와 쓰레드 기반 db 의 차이?
postgreSQL은 프로세스 기반 db 라고 한다.
•
장점
1.
single-process & multi-thread 기반인 경우, 프로세스 충돌이 일어났을 때 db 자체가 그냥 죽어버리게 된다
2.
쓰레드 관련 라이브러리가 OS 마다 상이하기 때문에 자잘한 오류가 많이 발생한다. (예로 BSD 계열 리눅스는 mysql 관련 해당 오류가 발생한다고)
3.
multi-thread 기반 db 는 시스템 자원에 대한 경합이 너무 심하다. (이 경합을 잘 조율하는 게 기술적으로 어렵기도 하기 때문에 버그가 자주 발생하기도 한다고) 등의 이유로 멀티 프로세스 방식을 채택하고 있다고 한다.
•
단점
1.
프로세스를 fork 하는 비용이 쓰레드에 비해 너무 크다. => 속도도 느림
2.
하나의 쿼리에 대해서 병렬처리를 할 수 없다. (멀티 프로세스로 병렬처리를 구현하더라도, 비효율적이다.)
3.
멀티 쓰레드가 병렬처리 시에 쓰레드 간 소통이 더 빠르다. 과 같은 단점들이 존재한다.
: 아마 멀티 프로세스를 사용하는 이유는 최적의 속도보다는, 시스템의 안정성을 추구하기 위함인 듯
: 시중에 다중 프로세스와 다중 쓰레드를 동시에 지원하는 db 도 있던 것 같았는데, 안정성과 속도를 적절히 잘 배합하려는 시도인 듯 하다.
3. 메모리 할당 및 사용 구조
: MySQL에서 사용되는 메모리 공간은 크게 글로벌 영역과 로컬 메모리 영역으로 나뉜다.
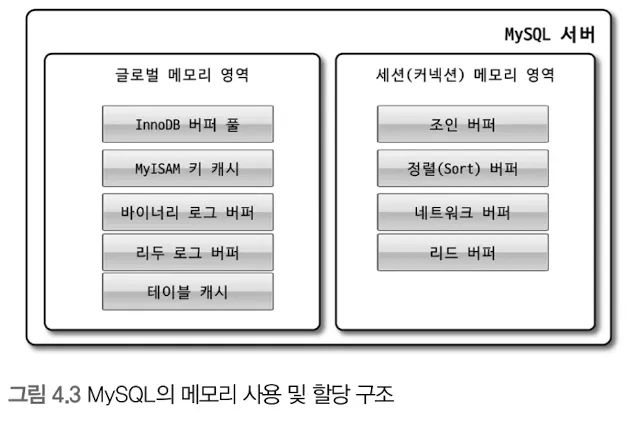
1.
글로벌 메모리 영역
서버가 시작되면서 운영체제로부터 할당된다.
모든 스레드에 의해 공유된다.
보통 하나의 메모리 공간만 할당되지만, 필요에 따라 2개 이상의 공간을 할당받을 수도 있다.
2.
로컬 메모리 영역
클라이언트 스레드가 쿼리를 처리하는데 사용하는 메모리 영역이다.
스레드 별로 공유되지 않는다.
쿼리의 용도별로 필요할 때만 공간이 할당된다.
4. 플러그인 스토리지 엔진 모델
•
MySQL 은 플러그인 형태로 다양한 스토리지 엔진을 제공
•
스토리지 엔진 뿐만 아니라, 인증이나 파서(parser) 등도 플러그인 형태로 제공되고, 직접 개발해서 사용 가능
•
스토리지 엔진의 데이터 읽기/쓰기 작업은 대부분 1건의 레코드 단위로 처리된다. group by 나 order by 등 복잡한 처리는 MySQL 엔진의 쿼리실행기 에서 처리
•
하나의 쿼리 작업은 여러 하위 작업으로 나뉘는데, 각 하위 작업이 MySQL 엔진 영역에서 처리되는지 아니면 스토리지 엔진 영역에서 처리되는지 구분할 줄 알아야한다.
SHOW ENGINES;
SHOW PLUGINS;
위와 같은 명령어로 설치되어 있는 스토리지 엔진과 플러그인을 확인할 수 있다.
5. 컴포넌트
: 기존 플러그인 아키텍처를 대체하기 위해 지원되는 기능,
•
플러그인의 단점
◦
플러그인은 MySQL 서버와 인터페이스할 수 있고, 플러그인끼리는 통신할 수 없다.
◦
MySQL 서버의 변수나 함수를 직접 호출하기 때문에 안전하지 않다.
◦
상호 의존관계를 설정할 수 없어서 초기화가 어렵다.
6. 쿼리 실행 구조
1.
쿼리 파서
sql 쿼리를 알맞은 토큰으로 분리 -> 트리 형태로 변환
쿼리 문장의 기본 문법 오류를 인식
2.
전처리기
토큰 트리를 문법으로 인식해, 문장에 구조적인 문제가 있는지 확인.
토큰을 테이블 이름이나, 내장 함수 등과 같은 개체를 매핑해 해당 객체의 존재 여부를 파악.
또는 해당 객체에 대한 접근 권한을 파악.
존재하지 않거나 접근 불가능한 토큰은 걸러진다.
3.
옵티마이저
sql문 최적화.
dbms의 두뇌에 해당.
4.
실행엔진(MySQL 엔진)
옵티마이저가 두뇌라면 실행엔진과 핸들러는 손과 발에 비유할 수 있다.
옵티마이저가 Group By를 처리하기 위해 임시 테이블을 사용하기로 결정한다고 했을 때,
•
실행 엔진이 핸들러에게 임시 테이블을 만들라고 요청
•
다시 실행 엔진은 where절에 일치하는 레코드를 읽어오라고 핸들러에게 요청
•
읽어온 레코드들을 1번에서 준비한 임시 테이블로 저장하라고 다시 핸들러에게 요청
•
데이터가 준비된 임시 테이블에서 필요하 방식으로 데이터를 읽어 오라고 핸들러에게 다시 요청
•
최종적으로 실행 엔진은 결과를 사용자나 다른 모듈로 넘김
5.
핸들러(스토리지 엔진)
MySQL 서버의 가장 밑단에서 MySQL 실행 엔진의 요청에 따라 데이터를 디스크로 저장하고 디스크로부터 읽어 오는 역할을 담당.
핸들러는 결국 스토리지 엔진을 의미하며 MyISAM 테이블을 조작하는 경우, 핸들러가 MyISAM 스토리지 엔진, InnoDB의 경우 핸들러가 InnoDB 스토리지 엔진\
7. 복제
: MySQL 서버에서 Replication은 매우 중요한 역할을 담당, 16장에서 따로 설명
8. 쿼리 캐시
: MySQL 8.0에선 제거 됨
•
이유
◦
기존에는 실행 결과를 메모리에 캐시하고 같은 쿼리가 들어오면 캐시된 결과를 반환했는데, 만약 그 사이에 데이터에 변경이 발생한다면!?
◦
데이터가 변경되었을 때 캐시에 저장된 결과중에서 변경된 테이블과 관련된 것들을 모두 삭제해야한다.
◦
심각한 동시 처리 성능 저하 유발 및 버그 발생 등의 문제 등으로 삭제됨
9. 스레드 풀
•
내부적으로 사용자의 요청을 처리하는 스레드 개수를 줄여 CPU가 제한된 개수의 스레트 처리에만 집중할 수 있게 해서 서버의 자원 소모를 줄이는 것이 목적
•
엔터프라이즈 에디션은 스레드 풀을 제공하지만, 커뮤니티 에디션은 Percona Server 에서 제공하는 플러그인 형태의 스레드 풀을 이용해야한다.
: MariaDB는 커뮤니티 버전도 지원!
10. 트랜잭션 지원 메타데이터
•
데이터 딕셔너리(메타데이터) : 테이블의 구조 정보와 스토어드 프로그램 등의 정보. 파일 기반으로 관리했었다. 파일 기반의 메타데이터는 트랜잭션을 지원하지 않기 때문에 테이블을 생성 또는 변경 중에 서버가 비정상 종료되면 테이블 깨지는 현상이 있었다.
•
8.0 버전부터는 데이터 딕셔너리를 모두 InnoDB의 테이블에 저장하도록 개선됐다. 시스템 테이블과 데이터 딕셔너리를 mysql DB에 저장한다. mysql DB는 통째로 mysql.ibd라는 이름의 테이블스페이스에 저장된다. 시스템 정보라 해당 db 에는 사용자가 접근할 수 없다.
•
MyISAM이나 CSV 등과 같은 스토리지 엔진의 메타 정보는 여전히 저장할 공간이 필요하다.
⇒ 대충 기존에는 트랜잭션이 없어서 막 저장하다 날라가고~ 그랬는데, 이제는 InnoDB에서 관리하니까 테이블 메타데이터가 안전하게 잘 저장된다~

